





Practical Data Center Security Practices For Organizations
Downtime and breaches hit small and midsize business (SMB) data centers hard, whether you manage colocated racks or a small on-premises server room. The 2025 IBM Cost of a Data Breach report pegs the global average breach cost at $4.4 million, and Uptime Institute data shows 54% of significant outages cost over $100,000. This guide gives you an action-first playbook that unifies physical, cyber, and operational controls without requiring enterprise budgets or large teams.
Implement checklists mapped to the National Institute of Standards and Technology (NIST) Cybersecurity Framework (CSF) 2.0 functions, aligned with Center for Internet Security (CIS) Controls v8.1 and the Cybersecurity and Infrastructure Security Agency (CISA) Cross-Sector Cybersecurity Performance Goals. Every section includes concrete steps you can execute with a small team.
The goal is straightforward: reduce incident likelihood, limit blast radius, and prove due diligence to customers and auditors.
Focus On A Few High-Impact Changes To Reduce Risk Fast
Layered controls paired with disciplined operations reduce both risk and recovery time. Prioritize these five high-impact moves over the next quarter:
- Deploy phishing-resistant multi-factor authentication (MFA) using FIDO2/WebAuthn for VPN, hypervisors, privileged access management (PAM) or jump hosts, and emergency accounts, then review privileged access monthly.
- Establish network segmentation with a dedicated management plane, default-deny policies between zones, and strong egress controls that explicitly restrict internet access from management and backup networks.
- Harden backups to a 3-2-1-1-0 pattern with one immutable or offline copy and quarterly restore drills.
- Lock down physical layers with mantraps, badge-plus-PIN-plus-biometric controls, anti-tailgating measures, cabinet locks, and clear escort policies for visitors and vendors.
- Centralize logs from physical access control systems (PACS), the building management system (BMS), uninterruptible power supplies (UPS), fire panels, and security tools into a security information and event management (SIEM) platform with alerts for privilege escalation and environmental anomalies.

Understand Threats And Failure Modes To Prioritize Controls
Understanding your adversaries and hazards lets you prioritize controls by real business impact. Cyber threats, operational hazards, and third-party risks each demand specific, outcome-focused countermeasures.
Cyber Threats
Phishing-led credential theft remains the top entry vector in environments of every size, targeting VPN, jump hosts, and cloud consoles, then enabling lateral movement toward hypervisors and storage. Ransomware increasingly aims at virtualization stacks and backup repositories to maximize leverage. Insider misuse can bypass perimeter defenses, so enforce separation of duties for high-risk operations and log administrative actions.
Physical and Environmental Failures
Power events cause the majority of impactful outages. Utility brownouts, automatic transfer switch (ATS) failures, uninterruptible power supply (UPS) battery faults, and generator start failures cascade into downtime when you do not engineer for graceful failover and test under load. Cooling anomalies, computer room air conditioner (CRAC) failures, water leaks, and fire incidents or false alarms all disrupt operations, and a single clogged filter or stuck ATS can quickly impact an entire room.
Business Impact Linkage
Define recovery time objective (RTO) and recovery point objective (RPO) for each service and map dependencies across power, network, storage, and identity. Quantify outage cost per hour to justify control investments. Use a simple risk register to sequence controls by impact and review it with leadership at least twice a year.
Build A Governance Baseline That Scales With Your Team
Lightweight governance keeps you compliant without bureaucratic overhead. The NIST CSF 2.0 Govern function turns policies, risk appetite, and control ownership into a simple, repeatable process for organizations of any size.
Policies, Roles, and Ownership
Publish clear facility access, media handling, and change control policies. Assign owners for each control domain and maintain a responsible, accountable, consulted, and informed (RACI) matrix for maintenance windows and emergency response. A simple risk register capturing threats, likelihood, impact, and planned mitigations keeps leadership informed and aligned.
Asset Inventory and Classification
Maintain a unified inventory spanning servers, hypervisors, switches, firewalls, UPS units, physical access control system (PACS) panels, generators, sensors, and out-of-band management devices. Classify data and systems by sensitivity, tagging crown jewels like identity stores, hypervisors, and key management services (KMS). Document network and data flows between zones to support segmentation design and incident investigation.
Layer Physical Security From Perimeter To Cabinet
Physical protections deter, detect, delay, and document intrusions from perimeter to cabinet. Verifiable access and quick investigations depend on consistent layering across all entry points.
Perimeter and Building Controls
Install fencing or bollards, secure parking, and bright LED lighting at the perimeter to discourage casual intruders. Staff or monitor entrances with intercoms, badge readers, cameras, and visitor check-in processes that verify government-issued identification. Use mantraps with badge-plus-PIN-plus-biometric authentication for restricted areas, enable anti-passback and anti-tailgating detection, and test interlocks at least quarterly.
Room, Cage, and Cabinet Protections
Server rooms need controlled doors with position sensors and alarms, plus visitor escort policies with signed-in logs that you review regularly. Cages require unique keyed or electronic locks, with no shared keys or codes across tenants or teams. Cabinets need high-security locks, blind panels, secured power distribution units (PDUs), and tamper-evident seals for particularly sensitive equipment.
Operations: Logging, Monitoring, and Revocation
Retain closed-circuit television (CCTV) footage for 30 to 90 days based on risk, with off-site or redundant storage for critical cameras. Send PACS events to your SIEM and build alerts for after-hours access, forced doors, repeated denied badge reads, and camera outages. Automate badge disablement upon HR termination and perform quarterly access recertifications for restricted zones, including contractors and vendors. For a deeper walk-through of typical components and integrations, see data center security systems.
Increase Power, Cooling, and Fire Resilience With Testing
Engineer for graceful failure because power remains the top driver of impactful outages. Redundancy without regular testing creates false confidence and can hide single points of failure.
Power Architecture and Testing
Deploy N+1 or better UPS capacity with maintenance bypass and monitor battery internal resistance. Size generators for full load plus margin, run quarterly start tests and annual load-bank tests, and maintain fuel quality with more than one delivery vendor. Test automatic transfer switches (ATS) periodically and track circuit capacity headroom at the panel and rack level.
Cooling and Environmental Controls
Implement hot and cold aisle separation or full containment and validate airflow with periodic thermal imaging. Schedule CRAC maintenance, filter changes, sensor calibration, and leak detection under raised floors and near CRACs, and integrate all related alarms into the BMS and SIEM so issues reach both facilities and security teams quickly.
Fire Protection
Pre-action sprinkler systems reduce accidental discharge risk. Clean-agent systems work for high-value rooms with sealed envelopes when correctly designed and maintained. Protect emergency power off (EPO) buttons with covers and signage, then conduct awareness drills to prevent accidental trips.
Use Network Architecture and Segmentation To Limit Blast Radius
Segment by function and sensitivity to minimize blast radius. Default-deny postures between zones limit lateral movement after initial compromise.
Segmentation Model
Create virtual routing and forwarding (VRF) instances or virtual LANs (VLANs) per zone covering production, management, backup, and operational technology or building management systems (OT/BMS). Apply default-deny access control lists (ACLs) between zones with allow-lists for application flows and named owners. Use stateful firewalls, log denied flows for tuning, and tighten rules as you learn normal traffic patterns.
Secure Management Plane
Build a dedicated management network with out-of-band access where possible and block management interfaces from user subnets and the internet. Enforce Secure Shell (SSH) and Transport Layer Security (TLS) with modern ciphers, disable legacy protocols, and rotate device credentials using centralized authentication such as Terminal Access Controller Access-Control System Plus (TACACS+) integrated with MFA. Record admin sessions via PAM or a jump host and alert on configuration changes to critical devices.
Egress Control
Default-deny lateral traffic using host firewalls and hypervisor-level controls so a single compromised workload cannot scan the entire environment. Restrict egress to required destinations, proxy outbound traffic for inspection, and avoid exposing management or backup endpoints directly to the internet.
Harden Identity and Admin Access With Strong MFA
Identity now functions as your perimeter, and phishing-resistant MFA blocks most credential-theft attacks. Privileged access management limits damage when credentials do get compromised by forcing high-risk actions through controlled workflows.
Phishing-Resistant MFA
Adopt FIDO2/WebAuthn hardware or platform authenticators for administrators and disable SMS or voice MFA for privileged access. Enforce MFA on VPN, cloud consoles, hypervisors, PAM or jump hosts, and emergency accounts. Set conditional access policies to block risky locations and unmanaged devices.
Privileged Access Management
Centralize privileged workflows with a PAM solution that enforces just-in-time and just-enough-administration—record admin sessions, store logs securely, and alert on privilege escalations or policy changes. Run monthly reviews of privileged groups and service accounts, and remove any dormant accounts.
Design Backup and Recovery To Survive Ransomware
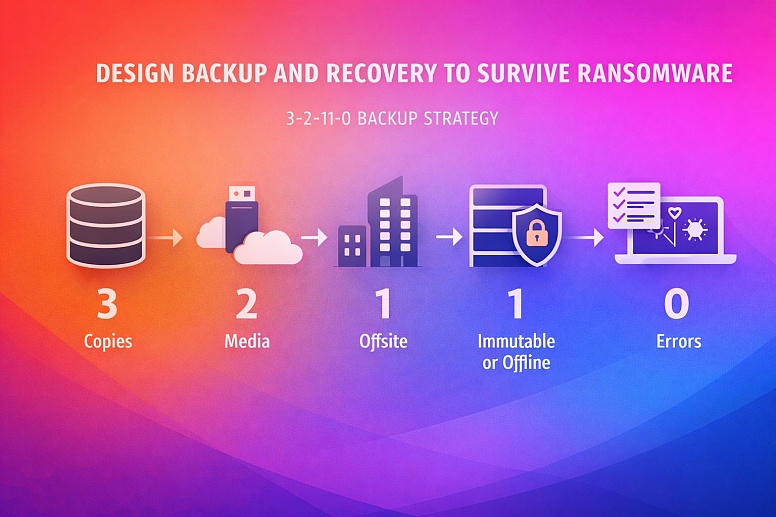
Backups must survive ransomware and operator error while still meeting RTO and RPO targets. The 3-2-1-1-0 pattern provides defense in depth and a clear design target.
Design the Backup Strategy
Maintain three copies on two different media, with one offsite and one immutable or offline. Back up hypervisor configurations, network device configurations, and key management service (KMS) metadata alongside data. Encrypt backups using Federal Information Processing Standards (FIPS) 140-3 validated modules where the option exists.
Protect Backup Systems
Isolate backup servers on dedicated networks and avoid domain-joining core backup infrastructure. Use MFA and role separation for backup administration, splitting retention changes from destructive operations. Monitor deletion and retention changes, restrict egress, and maintain strict allow-lists for remote management.
Test Restores
Run quarterly restore drills for critical applications and measure restore times against RTO. Document clean-room rebuild steps for identity, hypervisors, and storage, and store procedures offline. Automate periodic recovery verification to detect silent corruption by restoring sample data into an isolated test environment.
Unify Monitoring, Detection, and Logging Across IT and Facilities
Centralized telemetry shortens the mean time to detect and respond to both cyber and facility events. Targeted detections cut through noise.
Signals to Centralize
Aggregate PACS and CCTV events, power and cooling telemetry from UPS units and generators, and logs from firewalls, intrusion detection systems (IDS), endpoint detection and response (EDR), and hypervisors. Include NetFlow or similar network flow telemetry for traffic analysis.
Detection Content
Build detections for privilege and role changes on core systems, configuration drift from baselines, and out-of-window changes. Alert on sustained rack inlet temperatures above thresholds and repeated denied badge reads after hours.
Response Operations
Publish escalation matrices covering IT and facilities with on-call rotations. Run alert tuning sessions to reduce false positives and track mean time to detect and mean time to recover (MTTD/MTTR). Attach short step-by-step runbooks to alerts for faster triage.
Use A 30/60/90-Day Plan
Sequence quick wins and deeper work over 90 days to maximize risk reduction per dollar spent.
First 30 Days
- Complete IT and OT asset inventory; label crown jewels.
- Enforce MFA on VPN, hypervisors, and PAM.
- Lock cabinets and validate visitor vetting.
- Enable backup immutability and run a restore test.
Next 60 Days
- Establish baseline segmentation with default-deny and a dedicated management plane.
- Run table-top drills for power loss and ransomware.
- Set monthly patch windows and drift detection.
By 90 Days
- Correlate PACS events with SIEM detections.
- Segment OT/BMS with allow-lists.
- Conduct broader restore drills and prepare compliance readiness artifacts.
Keep Improving Data Center Security Over Time
Unified physical, cyber, and operational controls materially reduce breach and outage impacts for SMB data centers. Map controls to NIST CSF 2.0, validate them with drills and metrics, and iterate quarterly. Start with the 30/60/90-day plan, measure what matters, and adjust budgets based on results.











?")


0.1612